ReaderWriterQueue 是一个高性能的 C++无锁队列实现,专为单生产者-单消费者(SPSC)场景设计。
- 无锁设计:完全无锁实现,enqueue 和 dequeue 操作都是 O(1)时间复杂度
- 高性能:在 x86 架构上,内存屏障编译为无操作指令,性能极佳
- C++11 兼容:支持移动语义,减少不必要的拷贝
- 泛型模板:使用模版支持任意类型的元素,类似 std::queue
- 内存高效:预分配连续内存块,提供 try_enqueue 保证不分配内存
- 阻塞版本:提供 BlockingReaderWriterQueue 支持 wait_dequeue 操作
适用于需要在两个线程间高效传递数据的场景,如生产者-消费者模式、异步任务处理等。仅需包含头文件即可使用,无需额外依赖
核心问题
1. 整体思路
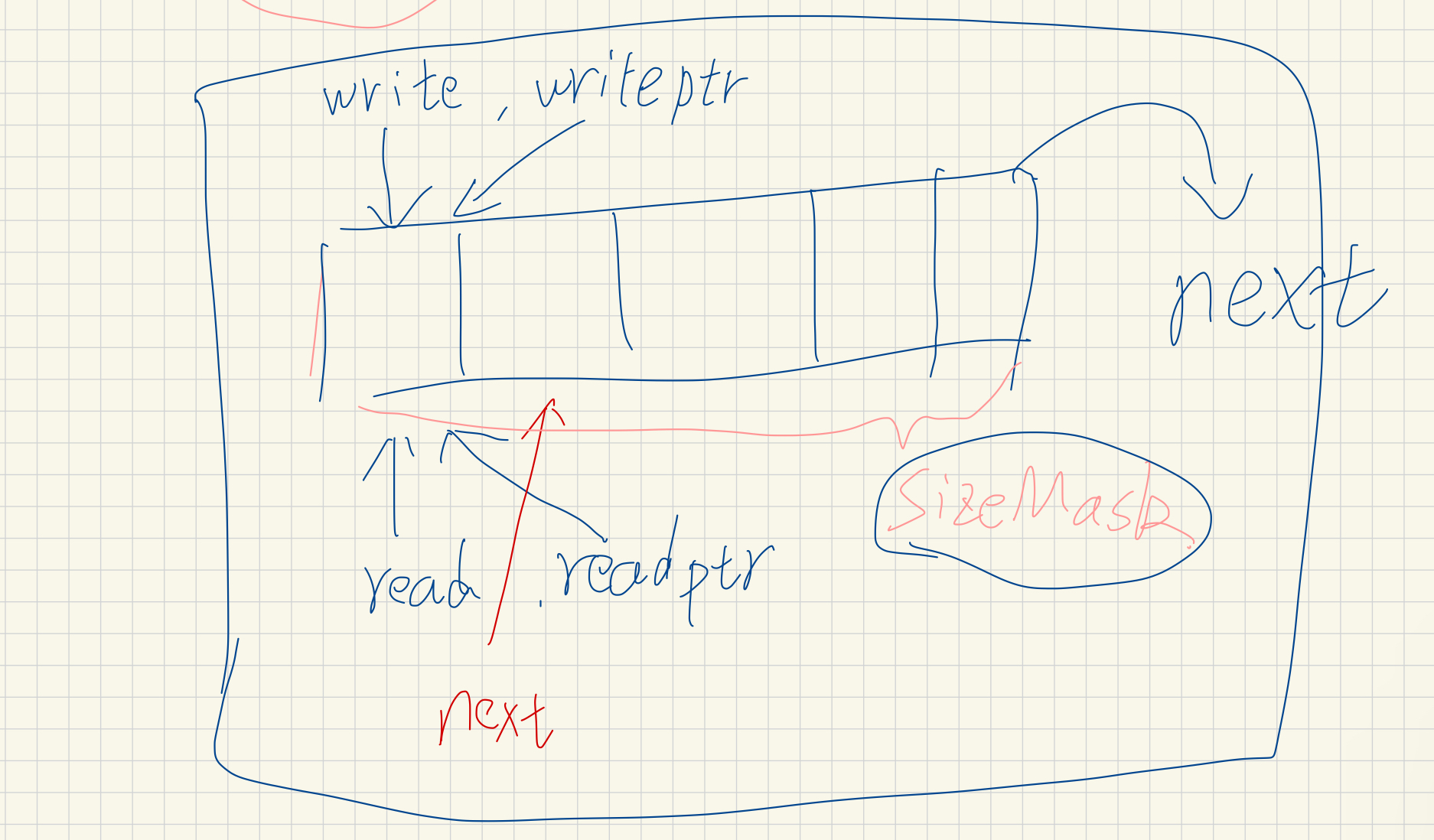
代码中主要包含两个部分,一个是队列链表,这个链表中存储很多的 block,每个 block 内部实现又是一个链表,这个链表,有读写两个指针,可以存放多个线程共享的元素
2. 内存中结构
存储的数据分为两部分,一部分是 Block 中属性数据+内存对其
auto size = sizeof(Block) + std::alignment_of<Block>::value - 1;
另一部分则是需要存储的具体数据:
size += sizeof(T) * capacity + std::alignment_of<T>::value - 1;
针对申请的内容,实际分配内存进行指针对齐
auto newBlockRaw = static_cast<char *>(std::malloc(size));
auto newBlockAligned = align_for<Block>(newBlockRaw);
auto newBlockData = align_for<T>(newBlockAligned + sizeof(Block));
template <typename U>
static AE_FORCEINLINE char *align_for(char *ptr) AE_NO_TSAN {
const std::size_t alignment = std::alignment_of<U>::value;
return ptr +
(alignment - (reinterpret_cast<std::uintptr_t>(ptr) % alignment)) %
alignment;
}
为什么这个过程中需要内存对其,可以看下下面的问题部分,这样对齐之后可以保证:
- Block 对象的内存访问是高效的
- 存储在队列中的 T 类型元素也能获得最佳的内存访问性能
- 避免因为未对齐访问导致的性能损失或在某些架构上的崩溃
3. 如何使用
测试
- 单元测试
- 稳定性测试
CRTP 设计模式
通过 CRTP,基类可以调用派生类的方法,实现了静态多态,在这个项目中是这样使用
核心思想
- “派生类告诉基类自己是谁” - 通过模板参数传递自身类型
- 静态多态 - 编译时确定调用关系,无运行时开销
- 类型安全 - 编译时检查,避免类型错误
优势
- 零运行时开销,相比虚函数性能强大很多(不使用虚函数表)
- 编译时类型检查(虚函数运行时多态,无法完全被优化)
- 代码复用(可以使用基类功能,派生类只需要实现特定的功能)
示例
- 基础示例
// CRTP 方法
template <typename Derived>
class CRTPBase {
public:
int calculate() { return static_cast<Derived *>(this)->calculate_impl(); }
};
class CRTPDerived : public CRTPBase<CRTPDerived> {
public:
int calculate_impl() { return 42; }
};
- 测试用例
#define REGISTER_TEST(testName) registerTest(#testName, &subclass_t::testName)
template <typename TSubclass> class TestClass {
public:
typedef TSubclass subclass_t;
void registerTest(const char *name, bool (subclass_t::*method)());
};
class Test : public TestClass<Test> {
public:
Test() {
REGISTER_TEST(test1);
REGISTER_TEST(test2);
}
bool test1();
bool test2();
};
测试过程中预定义宏
我来为您整理一个完整的 C/C++ 预定义宏表格:
C/C++ 预定义宏表
标准预定义宏
| 宏名 | 描述 | 类型 | 示例值 |
|---|---|---|---|
__LINE__ | 当前行号 | 整数 | 42 |
__FILE__ | 当前文件名 | 字符串 | "main.cpp" |
__DATE__ | 编译日期 | 字符串 | "Aug 20 2025" |
__TIME__ | 编译时间 | 字符串 | "14:30:25" |
__TIMESTAMP__ | 文件最后修改时间 | 字符串 | "Mon Aug 20 14:30:25 2025" |
C++ 函数/作用域相关宏
| 宏名 | 描述 | 类型 | 示例值 |
|---|---|---|---|
__func__ | 当前函数名 (C99/C++11) | 字符串 | "main" |
__FUNCTION__ | 当前函数名 (GCC 扩展) | 字符串 | "main" |
__PRETTY_FUNCTION__ | 完整函数签名 (GCC) | 字符串 | "int main(int, char**)" |
标准版本宏
| 宏名 | 描述 | 类型 | 示例值 |
|---|---|---|---|
__STDC__ | 符合标准 C | 整数 | 1 |
__STDC_VERSION__ | C 标准版本 | 整数 | 201112L (C11) |
__cplusplus | C++标准版本 | 整数 | 201703L (C++17) |
__STDC_HOSTED__ | 是否为宿主环境 | 整数 | 1 |
编译器特定宏
| 宏名 | 描述 | 编译器 | 示例值 |
|---|---|---|---|
__GNUC__ | GCC 主版本号 | GCC | 11 |
__GNUC_MINOR__ | GCC 次版本号 | GCC | 3 |
__clang__ | Clang 编译器 | Clang | 1 |
_MSC_VER | MSVC 版本 | MSVC | 1930 |
__INTEL_COMPILER | Intel 编译器版本 | ICC | 2021 |
平台/架构宏
| 宏名 | 描述 | 平台 | 示例值 |
|---|---|---|---|
_WIN32 | Windows (32/64 位) | Windows | 1 |
_WIN64 | Windows 64 位 | Windows | 1 |
__linux__ | Linux 系统 | Linux | 1 |
__APPLE__ | Apple 平台 | macOS/iOS | 1 |
__unix__ | Unix 系统 | Unix-like | 1 |
__x86_64__ | x86-64 架构 | 64 位 x86 | 1 |
__aarch64__ | ARM64 架构 | ARM64 | 1 |
调试相关宏
| 宏名 | 描述 | 类型 | 备注 |
|---|---|---|---|
NDEBUG | 发布模式 | 整数/未定义 | 定义时禁用 assert |
_DEBUG | 调试模式 | 整数 | MSVC 特定 |
DEBUG | 调试模式 | 整数 | 非标准 |
特殊用途宏
| 宏名 | 描述 | 类型 | 用途 |
|---|---|---|---|
__COUNTER__ | 递增计数器 | 整数 | 每次使用自增 |
__BASE_FILE__ | 主源文件名 | 字符串 | 编译单元的基础文件 |
__INCLUDE_LEVEL__ | 包含层级 | 整数 | 嵌套包含深度 |
特性检测宏 (C++11+)
| 宏名 | 描述 | 类型 | 示例值 |
|---|---|---|---|
__has_include | 检查头文件支持 | 函数宏 | __has_include |
__has_cpp_attribute | 检查 C++属性支持 | 函数宏 | __has_cpp_attribute(nodiscard) |
数值类型相关宏
| 宏名 | 描述 | 类型 | 示例值 |
|---|---|---|---|
__SIZEOF_INT__ | int 类型字节数 | 整数 | 4 |
__SIZEOF_POINTER__ | 指针字节数 | 整数 | 8 |
__CHAR_BIT__ | char 位数 | 整数 | 8 |
性能
- benchmarks
- SIMD 优化
问题
1. false sharing 问题
伪共享是指两个或多个 CPU 核心频繁访问同一缓存行中的不同数据,导致缓存行在不同核心之间不断传递,造成性能下降的现象。
缓存行(64字节):[变量A][变量B][其他数据...]
↑ ↑
核心1访问 核心2访问
虽然核心 1 只访问变量 A,核心 2 只访问变量 B,但因为它们在同一缓存行中:
核心 1 修改变量 A → 整个缓存行失效 核心 2 访问变量 B → 需要重新加载缓存行 核心 2 修改变量 B → 核心 1 的缓存行失效 核心 1 再次访问变量 A → 又需要重新加载
避免伪共享
使用 cachelineFiller0 将 front 和 tail 分隔到不同缓存行,生产者线程主要访问的 tail 和消费者线程主要访问的 front 不会相互干扰
struct Block {
weak_atomic<size_t> front; // 消费者主要访问
size_t localTail; // 消费者拥有
// 缓存行填充 - 确保下面的变量在不同缓存行
char cachelineFiller0[MOODYCAMEL_CACHE_LINE_SIZE - sizeof(weak_atomic<size_t>) - sizeof(size_t)];
weak_atomic<size_t> tail; // 生产者主要访问
size_t localFront; // 生产者拥有
// 再次填充
char cachelineFiller1[MOODYCAMEL_CACHE_LINE_SIZE - sizeof(weak_atomic<size_t>) - sizeof(size_t)];
weak_atomic<Block*> next;
// ...
};
2. 编译器重排序问题
- 指令重排序
- 内粗访问重新排序
- 循环优化重排序
问题示例
- 数据竞争:data 和 ready 没有同步保护,同时被多个线程访问
- 内存重排序:编译器/CPU 可能重排序指令,ready = true 可能在 data = 42 之前执行
- 可见性问题:一个线程的写操作可能不会立即对另一个线程可见
编译器可能将 producer 中的指令重排序为: // ready = true; // 被提前! // data = 42;// 被延后! // 这会导致消费者读取到错误的 data 值
#include <thread>
#include <iostream>
int data = 0;
bool ready = false;
// 线程1:生产者
void producer() {
data = 42;// Step 1
ready = true; // Step 2
}
// 线程2:消费者
void consumer() {
while (!ready) {
// 等待
}
std::cout << "Data: " << data << std::endl; // 期望输出42
}
解决编译器重排序问题
- 使用 volatile
volatile int flag = 0;
int data = 0;
void producer() {
data = 42;
flag = 1; // volatile 防止重排序
}
void consumer() {
while (flag ==0) { // volatile 防止优化
// 等待
}
printf("Data: %d\n", data);
}
- 使用 内存屏障
#include <atomic>
int data = 0;
bool ready = false;
void producer() {
data = 42;
std::atomic_signal_fence(std::memory_order_release); // 编译器屏障
ready = true;
}
void consumer() {
while (!ready) {std::atomic_signal_fence(std::memory_order_acquire); // 编译器屏障
}
printf("Data: %d\n", data);
}
- 使用原子操作
#include <atomic>
int data = 0;
std::atomic<bool> ready{false};
void producer() {
data = 42;
ready.store(true, std::memory_order_release); // 防止重排序
}
void consumer() {
while (!ready.load(std::memory_order_acquire)) {
// 等待
}
printf("Data: %d\n", data); // 保证读取到正确值
}
编译器重排序&CPU 重排序
| 特性 | 编译器重排序 | CPU 重排序 |
|---|---|---|
| 发生时机 | 编译时 | 运行时 |
| 影响范围 | 所有平台 | 特定 CPU 架构 |
| 防护方法 | 编译器屏障 | 内存屏障指令 |
| 性能影响 | 编译时优化 | 运行时开销 |
实践
- 单线程通常不用关心,但是多线程需要关系这个问题
3. 信号量
- 在 Apple iOS and OSX 平台上选用 Mach 信号量的原因:
4. 内存对齐
内存对齐是指数据在内存中的存储位置必须是某个特定数值的倍数。例如,一个 4 字节的整数可能需要存储在地址为 4 的倍数的位置上。
- 对齐的数据可以一次读取,不对其可能需要多次
- 对齐的数据更容易命中缓存
5. 多线程数据竞争和同步问题
| 特性/机制 | 互斥锁 (Mutex) | 读写锁 (Shared Mutex) | 原子操作 (Atomic Operations) |
|---|---|---|---|
| 并发性能 | 较差,锁竞争时性能下降 | 较好,读多写少时效果显著 | 非常好,几乎没有开销 |
| 写操作性能 | 好 | 差,写操作时锁竞争严重 | 非常好,原子操作通常不需要锁 |
| 读操作性能 | 较差,阻塞等待锁 | 好,允许多个读线程并行 | 非常好,读操作不需要锁 |
| 复杂度 | 低,易于理解和使用 | 中,管理读写锁和线程竞争 | 高,只有简单的操作可以用原子操作 |
| 适用场景 | 一般适用于少数临界区的保护 | 适合读多写少的场景 | 适合对单个变量的高效操作 |
| 开销 | 高,特别是在锁竞争严重时 | 中等,读写锁竞争时会有开销 | 低,原子操作无需阻塞 |